Linux协程分析
协程是一种用户态的轻量级线程。
实际上,每个运行上下文(ucontext_t)就直接对应于“协程”概念,对于协程的“创建”(Create)、“启动” (Spawn)、“挂起” (Suspend)、“切换” (Swap)等操作,很容易通过上面的4个API及其组合加以实现,需要的工作仅在于设计一组数据结构保存暂不运行的context结构,提供一些调度的策略即可。
1.1 ucontext_t结构体
typedef struct ucontext //用户级线程上下文
{
unsigned long int uc_flags;
struct ucontext *uc_link; //保存当前context结束后继续执行的context记录
stack_t uc_stack; //该context运行的栈信息
mcontext_t uc_mcontext; //保存具体的程序执行上下文——如PC值、堆栈指针、寄存器值等信息
__sigset_t uc_sigmask; //记录该context运行阶段需要屏蔽的信号
struct _libc_fpstate __fpregs_mem;
} ucontext_t;
typedef struct sigaltstack {
void *ss_sp; //栈顶指针
int ss_flags;
size_t ss_size; //栈大小
} stack_t;
1.2 函数定义
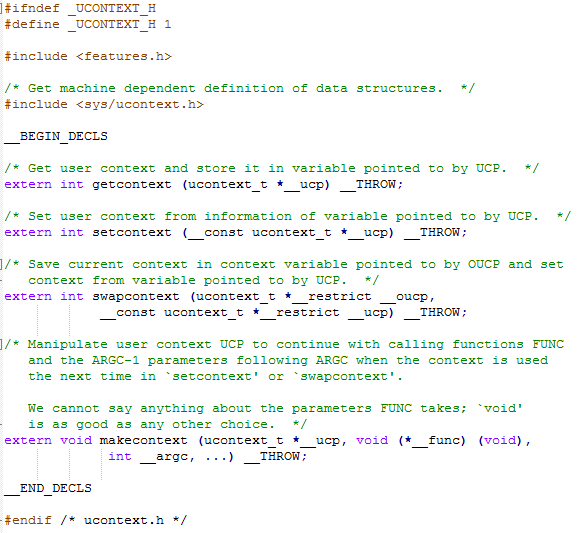
下面具体来看每个函数的功能:
• int makecontext(ucontext_t *ucp, void (*func)(), int argc, …) 该函数用以初始化一个ucontext_t类型的结构,也就是我们所说的用户执行上下文。函数指针func指明了该context的入口函数,argc指明入口参数个数,该值是可变的,但每个参数类型都是int型,这些参数紧随argc传入。 另外,在调用makecontext之前,一般还需要显式的指明其初始栈信息(栈指针SP及栈大小)和运行时的信号屏蔽掩码(signal mask)。 同时也可以指定uc_link字段,这样在func函数返回后,就会切换到uc_link指向的context继续执行。
makecontext修改通过getcontext取得的上下文ucp(这意味着调用makecontext前必须先调用getcontext)。然后给该上下文指定一个栈空间ucp->stack,设置后继的上下文ucp->uc_link.
当上下文通过setcontext或者swapcontext激活后,执行func函数,argc为func的参数个数,后面是func的参数序列。当func执行返回后,继承的上下文被激活,如果继承上下文为NULL时,线程退出。
• int setcontext(const ucontext_t *ucp) 该函数用来将当前程序执行线索切换到参数ucp所指向的上下文状态,在执行正确的情况下,该函数直接切入到新的执行状态,不再会返回。比如我们用上面介绍的makecontext初始化了一个新的上下文,并将入口指向某函数entry(),那么setcontext成功后就会马上运行entry()函数。
设置当前的上下文为ucp,setcontext的上下文ucp应该通过getcontext或者makecontext取得,如果调用成功则不返回。如果上下文是通过调用getcontext()取得,程序会继续执行这个调用。如果上下文是通过调用makecontext取得,程序会调用makecontext函数的第二个参数指向的函数,如果func函数返回,则恢复makecontext第一个参数指向的上下文第一个参数指向的上下文context_t中指向的uc_link.如果uc_link为NULL,则线程退出。
• int getcontext(ucontext_t *ucp) 该函数用来将当前执行状态上下文保存到一个ucontext_t结构中,若后续调用setcontext或swapcontext恢复该状态,则程序会沿着getcontext调用点之后继续执行,看起来好像刚从getcontext函数返回一样。 这个操作的功能和setjmp所起的作用类似,都是保存执行状态以便后续恢复执行,但需要重点指出的是:getcontext函数的返回值仅能表示本次操作是否执行正确,而不能用来区分是直接从getcontext操作返回,还是由于setcontext/swapcontex恢复状态导致的返回,这点与setjmp是不一样的。
• int swapcontext(ucontext_t *oucp, ucontext_t *ucp) 理论上,有了上面的3个函数,就可以满足需要了(后面讲的libgo就只用了这3个函数,而实际只需setcontext/getcontext就足矣了),但由于getcontext不能区分返回状态,因此编写上下文切换的代码时就需要保存额外的信息来进行判断,显得比较麻烦。 为了简化切换操作的实现,ucontext 机制里提供了swapcontext这个函数,用来“原子”地完成旧状态的保存和切换到新状态的工作(当然,这并非真正的原子操作,在多线程情况下也会引入一些调度方面的问题,后面会详细介绍)。
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
保存当前上下文到oucp结构体中,然后激活upc上下文。
如果执行成功,getcontext返回0,setcontext和swapcontext不返回;如果执行失败,getcontext,setcontext,swapcontext返回-1,并设置对于的errno.
简单说来, getcontext获取当前上下文,setcontext设置当前上下文,swapcontext切换上下文,makecontext创建一个新的上下文。
1.3 示例
1.3.1 示例1
#include <stdio.h>
#include <ucontext.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
ucontext_t context;
puts(“Hello”);
getcontext(&context);
puts(“Hello world”);
sleep(1);
setcontext(&context);
puts(“Hello2”);
return 0;
}
输出:
./ucontext1
Hello
Hello world
Hello world
…
1.3.2 示例2
#include <ucontext.h>
#include <stdio.h>
void func1(void * arg)
{
puts(“1”);
puts(“11”);
puts(“111”);
puts(“1111”);
}
void context_test()
{
char stack[1024*128];
ucontext_t child,main;
getcontext(&child); //获取当前上下文
child.uc_stack.ss_sp = stack;//指定栈空间
child.uc_stack.ss_size = sizeof(stack);//指定栈空间大小
child.uc_stack.ss_flags = 0;
child.uc_link = &main;//设置后继上下文
makecontext(&child,(void (*)(void))func1,0);//修改上下文指向func1函数
swapcontext(&main,&child);//切换到child上下文,保存当前上下文到main
puts(“main”);//如果设置了后继上下文,func1函数指向完后会返回此处
}
int main()
{
context_test();
return 0;
}
1.4 虚拟线程总结
\1. create初始化栈等分配内存,指定线程执行完后的下一个协程,若没有则结束协程。保存初始化位置
\2. delete:释放分配的内存
\3. sleep/weakup,唤醒后接着从sleep后执行
1.5 优点
l 运行在用户空间 首先是在用户空间,避免内核态和用户态的切换导致的成本。
l 由语言或者框架层调度
l 更小的栈空间允许创建大量实例(百万级别),
协程的切换开销远远小于内核对于线程的切换开销,
1.6 缺点
但遇到其他的瓶颈资源如何处理?比如带锁的共享资源,比如数据库连接等。互联网在线应用场景下,如果每个请求都扔到一个Goroutine里,当资源出现瓶颈的时候,会导致大量的Goroutine阻塞,最后用户请求超时。这时候就需要用Goroutine池来进行控流,同时问题又来了:池子里设置多少个Goroutine合适?
协同式多线程(collaborative multithreading)
一般来说coroutine用在异步的场景比较好,异步执行一般需要维护一个状态机,状态的维护需要保存在全局里或者你传进来的参数来,因为每一个状态回调都会重新被调用。
协程就是用户态线程,比内核线程低廉,切换阻塞成本低; 单调度器下,访问共享资源无需上锁,用于提高cpu单核的并发能力
缺点是 无法利用多核资源,只能开多进程才行,不过现在使用协程的语言都用到了多调度器的架构,单进程下的协程也能用多核了
1、我们在把一个由于协程可以在用户空间内切换上下文,不再需要陷入内核来做线程切换,避免了大量的用户空间和内核空间之间的数据拷贝,降低了CPU的消耗,从而避免了追求高并发时CPU早早到达瓶颈的窘境。
2、不再需要像异步编程时写那么一堆callback函数,代码结构不再支离破碎,整个代码逻辑上看上去和同步代码没什么区别,简单,易理解,优雅。